

La mejor manera de buscar duplicados depende del tipo de duplicados y de lo que debería ocurrir con los duplicados encontrados:
- Búsqueda inteligente de duplicados y direcciones duplicadas (deduplicación) con las herramientas DataQualityTools:
Se si desidera particolare comodità o se i doppioni da ricercare sono difficili da trovare, non si può fare a meno di un software appositamente progettato per questo problema. Las herramientas DataQualityTools encuentran duplicados incluso si difieren entre sí hasta cierto punto. Esto es especialmente útil para las listas de direcciones, donde los errores ortográficos y las variaciones ortográficas constituyen la regla y no la excepción. Más información ... - Suprimir duplicados con el comando 'distinct':
Si está buscando valores duplicados fáciles de encontrar, como números de cliente o artículo duplicados, y desea suprimirlos en el resultado de una consulta a una base de datos, puede utilizar el comando de SQL 'distinct'. Más información ... - Ocultar duplicados con el comando 'group by':
Si está buscando valores duplicados fáciles de encontrar, como números de cliente o artículo duplicados, y desea ocultarse en el resultado de una consulta a una base de datos, puede utilizar el comando de SQL 'gruop by '. Más información ... - Buscar duplicados con el comando 'select':
Si está buscando valores duplicados fáciles de encontrar, como números de cliente o artículo duplicados, y si los resultados encontrados deben eliminarse directamente de la base de datos o si los registros de datos deben completarse y complementarse sobre la base del resultado, se puede utilizar el comando de SQL 'select'. Más información ...
1. Búsqueda inteligente de duplicados y direcciones duplicadas (deduplicación) con las herramientas DataQualityTools en MariaDB
Las herramientas DataQualityTools encuentran duplicados incluso si difieren entre sí hasta cierto punto. Esto es especialmente útil para las listas de direcciones, donde los errores ortográficos y las variaciones ortográficas constituyen la regla y no la excepción. Proceda de la siguiente manera:
- Si previamente no lo ha hecho, descargue DataQualityTools gratuitamente desde aquí. Instale el programa y solicite una activación de prueba. Ahora podrá trabajar con el programa durante una semana sin restricciones.
- La función que necesitamos se encuentra en el menú dentro del bloque 'Deduplicación detro de una tabla'. Aquí seleccionamos 'Deduplicación universal'.
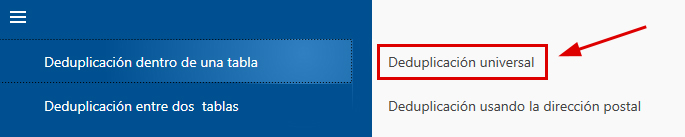
- Después de haber activado esta función, aparecerá en pantalla la administración de projecto. Aquí debe crear un proyecto nuevo con cualquier nombre y a continuación haga clic en el botón 'siguiente'.
- El siguiente paso es seleccionar la origen de datos con los datos a procesar. Para ello, seleccione MariaDB de la lista de selección en 'Formato / Acceso a'.
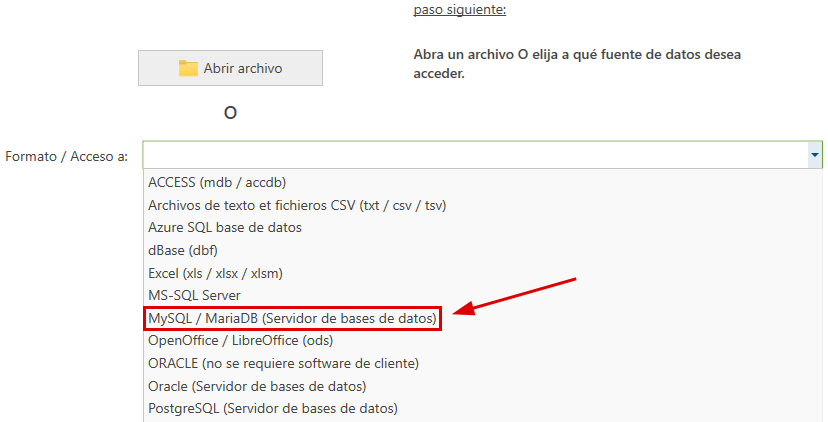
A continuación debemos introducir el nombre del servidor de base de datos. Después de hacer clic en el botón 'conectar con el servidor' debemos introducir los datos de acceso. La selección de la base de datos deseada y de la tabla de ahí resultante resulta finalmente de los correspondientes listados de selección. - A continuación, debe indicar al programa qué columnas de la tabla desea comparar:
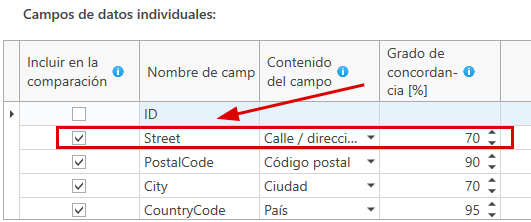
En este ejemplo hay que comparar la columna Street, entre otras. Contiene el nombre de la calle, por lo que se seleccionó 'Street' de la lista de selección para el contenido del campo. Y se ha elegido un 50 % como umbral para el grado de concordancia. Así, el nombre de la calle tiene que ser al menos un 50 % idéntico, de modo que el registro de datos se encuentre en el resultado.
Si es necesario, también se pueden combinar columnas individuales para formar un grupo:
De esta manera el contenido de las columnas se resume en el grupo antes de la comparación y, por lo tanto, se comparan entre sí. - Haciendo clic en el botón 'Siguiente' llegamos a un diálogo con más opciones. Pero no las necesitamos aquí.
- Haciendo clic en el botón 'siguiente', iniciamos la búsqueda de duplicados. Después de muy poco tiempo se muestra un resumen de los resultados. Si el programa encontró duplicados en la tabla a procesar, entonces, haciendo clic en el botón 'Modificar' conduce a una vista general del resultado:
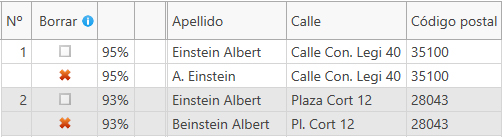
Aquí el resultado de la comparación se expone en forma de tabla. Y aquí los registros que deben ser borrados estarán marcados con una cruz roja, ésta se podrá eliminar cuando sea necesario. - Finalmente, el resultado se tiene que procesar más. Por ejemplo, podríamos marcar los registros marcados para borrado directamente en la tabla fuente de MariaDB con una marca de borrado. Para ello, seleccionamos la función adecuada haciendo clic en 'Funciones de marcado':

Y luego haga clic en 'Marcar en la tabla de origen':
Infine, si deve specificare come debba apparire concretamente il contrassegno e in quale campo dati debba essere scritto: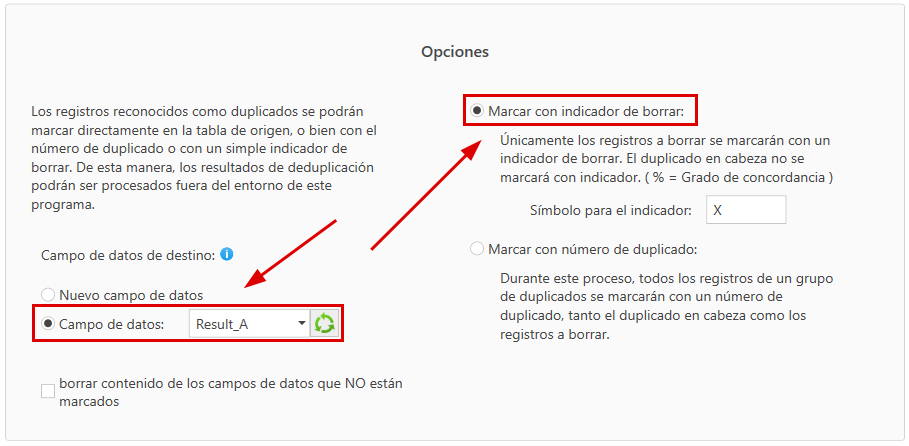
2. Suprimir duplicados con el comando 'distinct' en MariaDB
Suponga que de la tabla con los artículos pedidos deben determinarse todos los números de artículo que un cliente individual ha pedido, por lo que en el resultado cada número de artículo puede aparecer con un cliente solo una vez. La consulta de la base de datos para hacer esto podría ser así:
SELECT DISTINCT customer_id, article_no
FROM customer_articles
ORDER BY customer_no, article_no
El 'distinct' se refiere a todas las columnas especificadas en 'select'. Como resultado, cada número de artículo se enumera aquí con cada número de cliente, pero cada combinación de número de artículo y número de cliente se enumera solamente una vez. En combinación con el comando 'into', también puede limpiar una tabla de registros duplicados:
SELECT DISTINCT customer_id, article_no
INTO table_new
FROM customer_articles
ORDER BY customer_no, article_no
Los datos limpios de duplicados se escriben en una nueva tabla.
3. Ocultar duplicados con el comando 'group by' en MariaDB
Supongamos que los números de artículo deben determinarse a partir de la tabla con los artículos pedidos, de modo que en el resultado cada número de artículo solo puede aparecer una vez. La consulta de la base de datos para hacer esto podría ser así:
SELECT article_no, COUNT(*), SUM(revenue)
FROM invoice_articles
GROUP BY article_no
ORDER BY COUNT(*), article_no
Además del número de artículo, esta consulta devuelve el número de registros que contienen este número de artículo y la suma de las ventas de estos registros.
4. Buscar duplicados con el comando 'select' en MariaDB
Con las consultas de SQL resulta relativamente sencillo encontrar duplicados exactos, o sea, aquellos registros duplicados en que todos los resultados coinciden carácter por carácter a excepción de las mayúsculas y minúsculas. Por ejemplo, en la siguiente consulta MariaDB devuelve todos los registros en los que coincide el contenido del campo de datos 'name':
SELECT tab1.id, tab1.name, tab2.id, tab2.name
FROM tablename tab1, tablename tab2
WHERE tab1.name=tab2.name
AND tab1.id<>tab2.id
AND tab1.id=(SELECT MAX(id) FROM tablename tab
WHERE tab.name=tab1.name)
Como se puede observar, para este comando de SQL se requiere una columna con una ID que identifica el registro de datos correspondiente de manera inequívoca para garantizar que un registro de datos no se compare consigo mismo. Asimismo, esta ID se requiere para garantizar que el registro de datos con la mayor ID solo figure en la columna "tab1.id" y no en la columna "tab2.id". De este modo, se evita que el registro de datos con la mayor ID se elimine también de un grupo de duplicados. Las ID de los registros de datos que se vayan a eliminar figuran en la columna "tab2.id". El resultado, incorporado en un comando DELETE para MariaDB, se ve de la siguiente manera:
DELETE FROM tablename
WHERE id IN
(SELECT tab2.id
FROM tablename tab1, tablename tab2
WHERE tab1.name=tab2.name
AND tab1.id<>tab2.id
AND tab1.id=(SELECT MAX(id) FROM tablename tab
WHERE tab.name=tab1.name))
Como es natural, este comando de SQL se puede ampliar fácilmente de tal manera que, además del contenido del campo de datos 'name', también se comparen otros campos de datos, p. ej. aquellos que contienen la dirección postal de forma conjunta.
En el artículo 'Búsqueda difusa de duplicados con SQL', podrá informarse de las posibilidades que ofrece SQL a la hora de buscar duplicados difusos. No obstante, este problema solo se puede solucionar de manera satisfactoria con herramientas especializadas que ofrecen una búsqueda de registros duplicados con tolerancia a fallos, p. ej. DataQualityTools.